

Generative AI will have a transformative impact on every business. Databricks has been pioneering AI innovations for a decade, actively collaborating with thousands of customers to deliver AI solutions, and working with the open source community on projects like MLflow, with 11 million monthly downloads. With Lakehouse AI and its unique data-centric approach, we empower customers to develop and deploy AI models with speed, reliability, and full governance. Today at the Data and AI Summit, we announced several new capabilities that establish Lakehouse AI as the premier platform to accelerate your generative AI production journey. These innovations include Vector Search, Lakehouse Monitoring, GPU-powered Model Serving optimized for LLMs, MLflow 2.5, and more.
Key challenges with developing generative AI solutions
Optimizing Model Quality: Data is the heart of AI. Poor data can lead to biases, hallucinations, and toxic output. It is difficult to effectively evaluate Large Language Models (LLMs) as these models rarely have an objective ground truth label. Due to this, organizations often struggle to understand when the model can be trusted in critical use cases without supervision.
Cost and complexity of training with enterprise data: Organizations are looking to train their models using their own data and control them. Instruction-tuned models like MPT-7B and Falcon-7B have demonstrated that with good data, smaller fine-tuned models can get good performance. However, organizations struggle to know how many data examples are enough, which base model they should start with, to manage the complexities of the infrastructure required to train and fine-tune models, and how to think about costs.
Trusting Models in Production: With the technology landscape rapidly evolving and new capabilities being introduced, it’s more challenging to get these models into production. Sometimes these capabilities come in the form of needs for new services such as a vector database while other times it may be new interfaces such as deep prompt engineering support and tracking. Trusting models in production is difficult without robust and scalable infrastructure, and a stack fully instrumented for monitoring.
Data security and governance: Organizations want to control what data is sent to and stored by third-parties to prevent data leakage as well as ensure responses are conforming to regulation. We’ve seen cases where teams have unrestricted practices today that compromise security and privacy or have cumbersome processes for data usage that impede speed of innovation.
Lakehouse AI – Optimized for Generative AI
To solve the aforementioned challenges, we are excited to announce several Lakehouse AI capabilities that will help organizations maintain data security and governance as well as accelerate their journey from proof-of-concept to production.
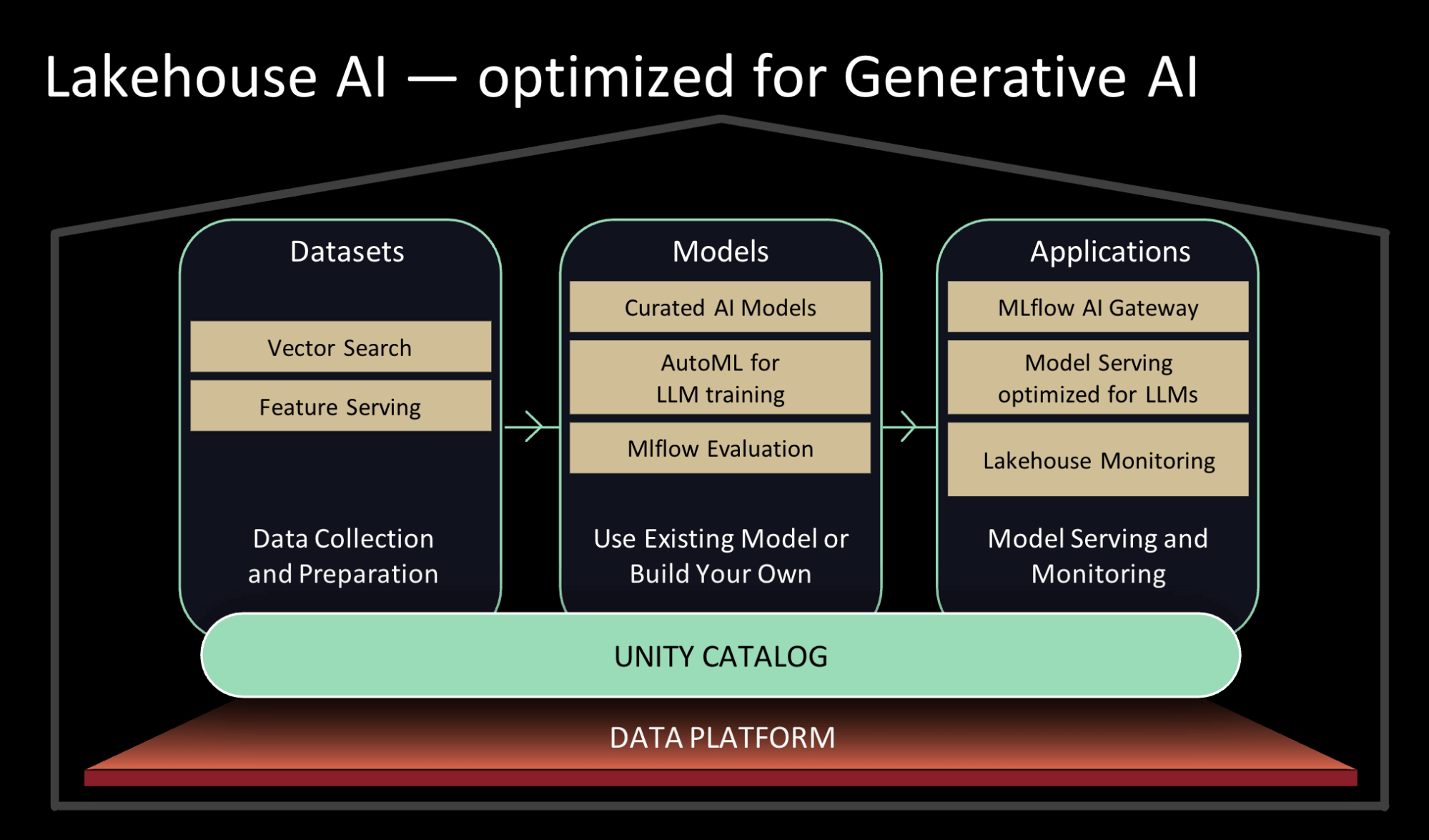
Use existing models or train your own model using your data
- Vector Search for indexing: With Vector Embeddings, organizations can leverage the power of Generative AI and LLMs across many use cases, from customer support bots by your organization’s entire corpus of knowledge to search and recommendation experiences that understand customer intent. Our vector database helps teams quickly index their organizations’ data as embedding vectors and perform low-latency vector similarity searches in real-time deployments. Vector Search is tightly integrated with the Lakehouse, including Unity Catalog for governance and Model Serving to automatically manage the process of converting data and queries into vectors. Sign up for preview here.
- Curated models, backed by optimized Model Serving for high performance: Rather than spending time researching the best open source generative AI models for your use case, you can rely on models curated by Databricks experts for common use cases. Our team continually monitors the landscape of models, testing new models that come out for many factors like quality and speed. We make best-of-breed foundational models available in the Databricks Marketplace and task-specific LLMs available in the default Unity Catalog. Once the models are in your Unity Catalog you can directly use or fine-tune them with your data. For each of these models, we further optimize Lakehouse AI’s components – for example, decreasing model serving latency by up to 10X. Sign up for the preview here.
- AutoML support for LLMs: We’ve expanded AutoML offering to support fine tuning generative AI models for text classification as well fine-tune base embedding models with your data. AutoML enables non-technical users to fine-tune models with point-and-click ease on your organization’s data, and increases the efficiency of technical users doing the same. Sign up for preview here.
Monitor, evaluate, and log your model and prompt performance
- Lakehouse Monitoring: The first unified data and AI monitoring service that allows users to simultaneously track the quality of both their data and AI assets. The service maintains profile and drift metrics on your assets, lets you configure proactive alerts, auto-generates quality dashboards to visualize and share across your organization, and facilitates root-cause analysis by correlating data-quality alerts across the lineage graph . Built on Unity Catalog, Lakehouse Monitoring provides users with deep insights into their data and AI assets to ensure high quality, accuracy, and reliability. Sign up for preview here.
- Inference Tables: As part of our data-centric paradigm, the incoming requests and outgoing responses to serving endpoints are logged to Delta tables in your Unity Catalog. This automatic payload logging enables teams to monitor the quality of their models in near real-time, and the table can be used to easily source data points that need to be relabeled as the next dataset to fine tune your embeddings or other LLMs.
- MLflow for LLMOps (MLflow2.4 and MLflow2.5): We’ve expanded the MLflow evaluation API to track LLM parameters and models to more easily identify the best model candidate for your LLM use case. We’ve built prompt engineering tools to help you identify the best prompt template for your use case. Each prompt template evaluated is recorded by MLflow to examine or reuse later.
Securely serve models, features, and functions in real-time
- Model Serving, GPU-powered and optimized for LLMs: Not only are we providing GPU model serving, but also we are optimizing our GPU serving for the top open source LLMs. Our optimizations provide best-in-class performance, enabling LLMs to run an order of magnitude faster when deployed on Databricks. These performance improvements allow teams to save costs at inference time as well as allow endpoints to scale up/down quickly to handle traffic. Sign up for preview here.
“Moving to Databricks Model Serving has reduced our inference latency by 10x, helping us deliver relevant, accurate predictions even faster to our customers. By doing model serving on the same platform where our data lives and where we train models, we have been able to accelerate deployments and reduce maintenance.”— Daniel Edsgärd, Head of Data Science, Electrolux
- Feature & Function Serving: Organizations can prevent online and offline skew by serving both features and functions. Feature and Function Serving performs low latency, on-demand computations behind a REST API endpoint to serve machine learning models and power LLM applications. When used in conjunction with Databricks Model Serving, features are automagically joined with the incoming inference request–allowing customers to build simple data pipelines. Sign up for preview here.
- AI Functions: Data analysts and data engineers can now use LLMs and other machine learning models within an interactive SQL query or SQL/Spark ETL pipeline. With AI Functions, an analyst can perform sentiment analysis or summarize transcripts–if they have been granted permissions in the Unity Catalog and AI Gateway. Similarly, a data engineer could build a pipeline that transcribes every new call center call and performs further analysis using LLMs to extract critical business insights from those calls.
Manage Data & Governance
- Unified Data & AI Governance: We are enhancing the Unity Catalog to provide comprehensive governance and lineage tracking of both data and AI assets in a single unified experience. This means the Model Registry and Feature Store have been merged into the Unity Catalog, allowing teams to share assets across workspaces and manage their data alongside their AI.
- MLflow AI Gateway: As organizations are empowering their employees to leverage OpenAI and other LLM providers, they are running into issues managing rate limits and credentials, burgeoning costs, and tracking what data is sent externally. The MLflow AI Gateway, part of MLflow 2.5, is a workspace-level API gateway that allows organizations to create and share routes, which then can be configured with various rate limits, caching, cost attribution, etc. to manage costs and usage.
- Databricks CLI for MLOps: This evolution of the Databricks CLI allows data teams to set up projects with infra-as-code and get to production faster with integrated CI/CD tooling. Organizations can create “bundles” to automate AI lifecycle components with Databricks Workflows.
In this new era of generative AI, we are excited about all these innovations we have released and look forward to what you will build with these!
Source: databricks



